本文介绍 vLLM 中的分离式预填充功能。
注意
此功能为实验性功能,可能会发生变化。
为什么需要分离式预填充?
主要有两个原因:
-
分别优化首 token 时间 (TTFT) 和 token 间延迟 (ITL) 分离式预填充将 LLM 推理的预填充和解码阶段放在不同的 vLLM 实例中。这使您可以灵活地为预填充和解码分配不同的并行策略(例如
tp和pp),从而在不影响 ITL 的情况下优化 TTFT,或在不影响 TTFT 的情况下优化 ITL。 -
控制尾部 ITL 在没有分离式预填充的情况下,vLLM 可能会在某个请求的解码过程中插入一些预填充任务,从而导致更高的尾部延迟。分离式预填充帮助您解决此问题并控制尾部 ITL。虽然通过适当的块大小进行分块预填充也可以实现相同的目标,但在实践中很难确定正确的块大小值。因此,分离式预填充是控制尾部 ITL 的更可靠方法。
注意
分离式预填充不会提高吞吐量。
使用示例
请参考 examples/online_serving/disaggregated_prefill.sh 了解分离式预填充的示例用法。
基准测试
请参考 benchmarks/disagg_benchmarks/ 查看分离式预填充的基准测试。
开发实现
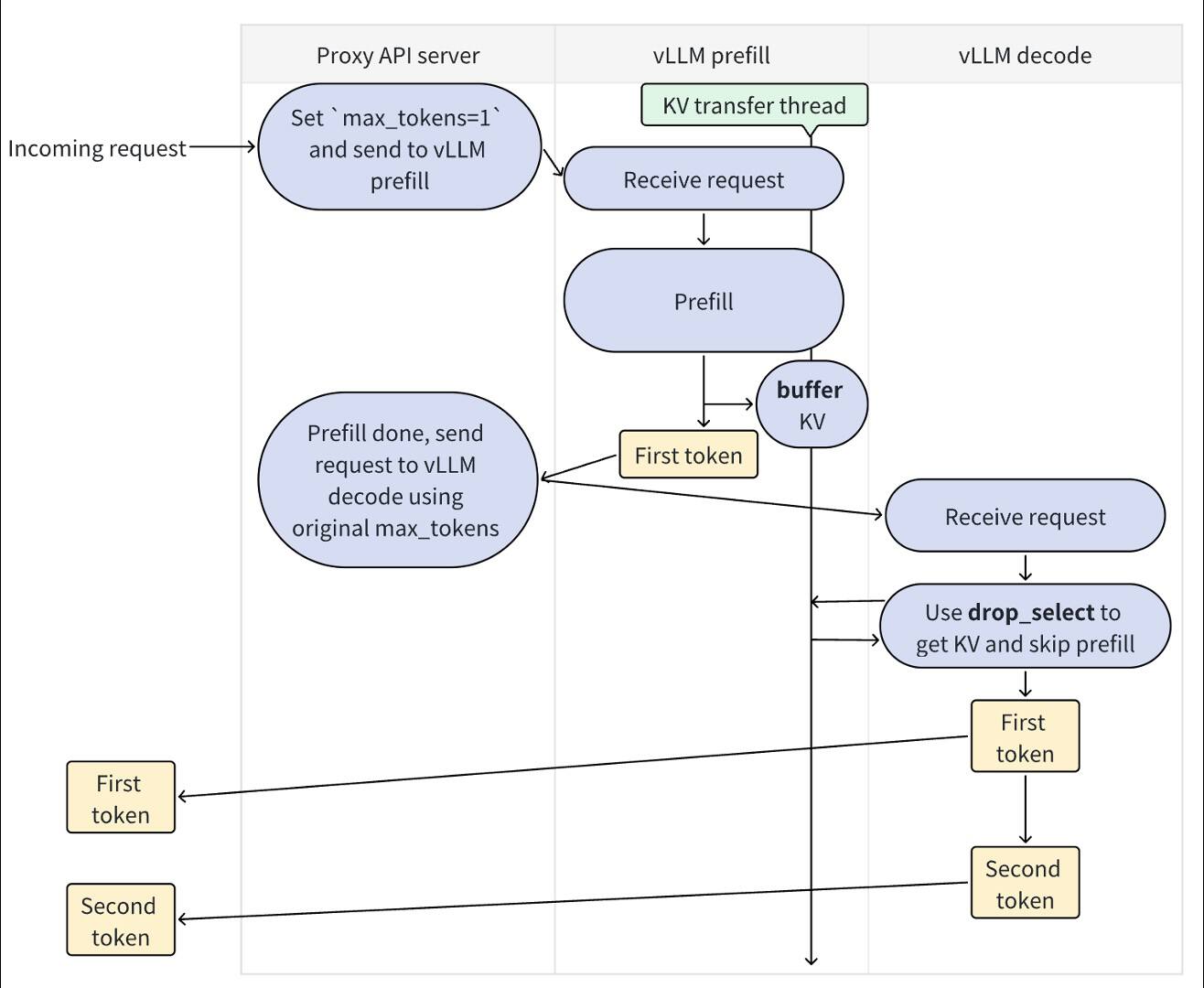
我们通过运行 2 个 vLLM 实例来实现分离式预填充:一个用于预填充(称为预填充实例),另一个用于解码(称为解码实例),然后使用连接器将预填充的 KV 缓存和结果从预填充实例传输到解码实例。
所有分离式预填充的实现都在 vllm/distributed/kv_transfer 目录下。
分离式预填充的关键抽象:
-
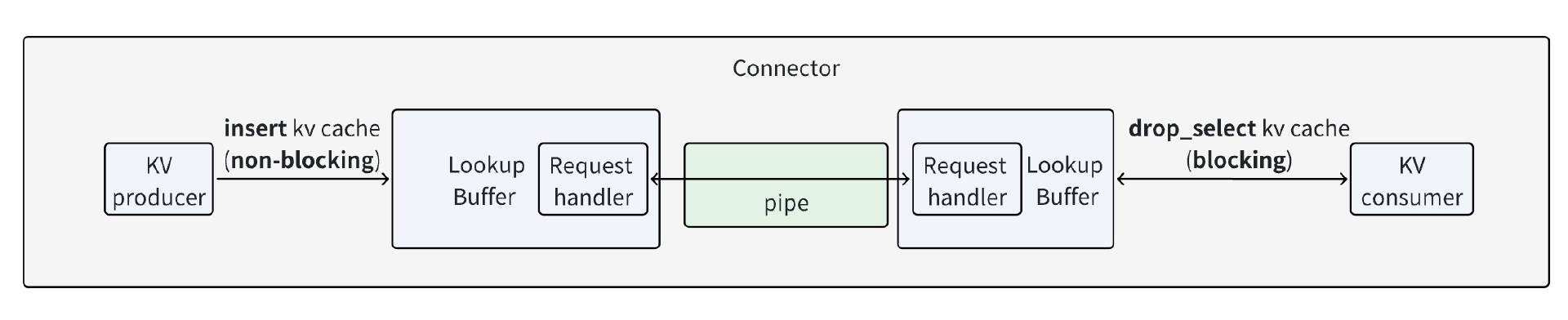
连接器 (Connector): 连接器允许 KV 消费者从 KV 生产者中检索一批请求的 KV 缓存。
-
查找缓冲区 (LookupBuffer): 查找缓冲区提供两个 API:
insertKV 缓存和drop_selectKV 缓存。insert和drop_select的语义类似于 SQL,其中insert将 KV 缓存插入缓冲区,而drop_select返回符合给定条件的 KV 缓存并将其从缓冲区中删除。 -
管道(Pipe): 用于张量传输的单向 FIFO 管道。它支持
send_tensor和recv_tensor。
注意
insert是非阻塞操作,但drop_select是阻塞操作。
以下是说明上述 3 个抽象如何组织的图示:
分离式预填充的工作流程如下:
buffer 对应于 LookupBuffer 中的 insert API,而 drop_select 对应于 LookupBuffer 中的 drop_select API。
第三方贡献
分离式预填充与基础设施高度相关,因此 vLLM 依赖第三方连接器来实现生产级的分离式预填充(vLLM 团队将积极审查并合并第三方连接器的新 PR)。
我们推荐 3 种实现方式:
-
完全自定义的连接器: 实现您自己的
Connector,并调用第三方库来发送和接收 KV 缓存,以及更多操作(例如编辑 vLLM 的模型输入以执行自定义预填充等)。这种方法为您提供了最大的控制权,但存在与未来 vLLM 版本不兼容的风险。 -
类似数据库的连接器: 实现您自己的
LookupBuffer并支持类似于 SQL 的insert和drop_selectAPI。 -
分布式点对点连接器: 实现您自己的
Pipe并支持send_tensor和recv_tensorAPI,类似于torch.distributed。