vLLM 分页注意力
-
目前,vLLM 使用自己的多头查询注意力内核实现(
csrc/attention/attention_kernels.cu)。该内核旨在兼容 vLLM 的分页键值缓存,其中键和值缓存存储在不同的块中(注意,这里的块概念与 GPU 线程块不同。因此,在后续文档中,将把 vLLM 分页注意力块称为「块」,而把 GPU 线程块称为「线程块」)。 -
为了实现高性能,该内核依赖于专门设计的内存布局和访问方法,特别是在线程从全局内存读取数据到共享内存时。本文档的目的是逐步提供内核实现的高层次解释,以帮助那些希望了解 vLLM 多头查询注意力内核的人。在阅读完本文档后,用户能够更好地理解,并更容易跟随实际的实现。
-
请注意,本文件可能不涵盖所有细节,例如如何计算相应数据的正确索引或点乘实现。不过,在阅读完本文档并熟悉高层次的逻辑流程后,您应该更容易阅读实际代码并理解细节。
输入
- 内核函数采用当前线程的参数列表来执行其分配的工作。3 个最重要的参数是输入指针
q、k_cache和v_cache,它们指向全局内存上需要读取和处理的查询、键和值数据。输出指针out指向应将结果写入的全局内存。这四个指针实际上引用的是多维数组,但每个线程只访问分配给它的那部分数据。为了简单起见,我在这里省略了所有其他运行时参数。
template<
typename scalar_t,
int HEAD_SIZE,
int BLOCK_SIZE,
int NUM_THREADS,
int PARTITION_SIZE = 0>
__device__ void paged_attention_kernel(
... // Other side args. // 其他副参数
const scalar_t* __restrict__ out, // [num_seqs, num_heads, max_num_partitions, head_size]
const scalar_t* __restrict__ q, // [num_seqs, num_heads, head_size]
const scalar_t* __restrict__ k_cache, // [num_blocks, num_kv_heads, head_size/x, block_size, x]
const scalar_t* __restrict__ v_cache, // [num_blocks, num_kv_heads, head_size, block_size]
... // Other side args.
)
-
在编译时确定的函数签名上方还有一个模板参数列表。
scalar_t表示查询、键和值数据元素的数据类型,例如 FP16。HEAD_SIZE表示每个头中的元素数量。BLOCK_SIZE是指每个块中的 token 数量。NUM_THREADS表示每个线程块中的线程数。PARTITION_SIZE表示张量并行 GPU 的数量(为简单起见,我们假设这是 0 且禁用张量并行)。 -
使用这些参数,我们需要进行一系列的准备工作。包括计算当前的头索引、块索引和其他必要的变量。不过,目前我们可以忽略这些准备工作,直接进行实际的计算。一旦掌握了整个流程,就会更容易理解它们。
概念
-
在我们深入讨论计算流程之前,我想先描述一下后面部分所需的一些概念。不过,若是您遇到任何令人困惑的术语,您可以先跳过本节并在之后回来。
-
序列:序列代表客户端请求。例如,
q指向的数据具有[num_seqs,num_heads,head_size]的形状。这表示q指向总共num_seqs个查询序列数据。由于该内核是单个查询注意力内核,因此每个序列只有一个查询 token 。因此,num_seqs等于批次中处理的 token 总数。 -
上下文:上下文由序列中生成的 token 组成。例如,
["What" , "is" , "your"]是上下文 token ,输入查询 token 是"name"。该模型可能会生成 token?。 -
Vec:vec 是同时被获取和计算的元素的列表。对于查询和键数据,确定 vec 大小 (
VEC_SIZE),以便每个线程组一次可以获取和计算 16 字节的数据。对于值数据,确定 vec 大小 (V_VEC_SIZE),以便每个线程一次可以获取和计算 16 字节的数据。例如,如果scalar_t为 FP16(2 字节) 且THREAD_GROUP_SIZE为 2,则VEC_SIZE将为 4,而V_VEC_SIZE将为 8。 -
线程组:线程组是一小组线程 (
THREAD_GROUP_SIZE),一次获取并计算一个查询 token 和一个键 token。每个线程仅处理 token 数据的一部分。一个线程组处理的元素总数称为x。例如,如果线程组包含 2 个线程,头大小为 8,则线程 0 处理索引 0、2、4、6 处的查询和键元素,而线程 1 处理索引 1、3、5、7。 -
块:vLLM 中的键和值缓存数据被分成块。每个块在一个头中存储固定数量 (
BLOCK_SIZE)token 的数据。每个块可能仅包含整个上下文 token 的一部分。例如,如果块大小为 16,头大小为 128,那么对于 1 个头,1 个块可以存储 16 * 128 = 2048 个元素。 -
Warp:Warp 是一组 32 个线程(
WARP_SIZE),它们在流多处理器 (SM) 上同时执行。在这个内核中,每个 warp 同时处理一个查询 token 与一个完整块的键 token 之间的计算(它可以在多次迭代中处理多个块)。例如,如果有 4 个 warp 和 6 个块用于一个上下文,那么分配方式将是:warp 0 处理第 0 和第 4 块,warp 1 处理第 1 和第 5 块,warp 2 处理第 2 块,warp 3 处理第 3 块。 -
线程块:线程块是一组可以访问同一共享内存的线程 (
NUM_THREADS)。每个线程块包含多个 warp (NUM_WARPS),在这个内核中,每个线程块处理一个查询 token 和整个上下文的键 token 之间的计算。 -
网格: 网格是线程块的集合,并定义集合的形状。在此内核中,形状为
(num_heads, num_seqs, max_num_partitions)。因此,每个线程块只处理一个头、一个序列、一个分区的计算。
查询
- 本节将介绍查询数据如何存储在内存中以及如何由每个线程获取。如上所述,每个线程组获取一个查询 token 数据,而每个线程本身仅处理一个查询 token 数据的一部分。在每个 warp 中,每个线程组将获取相同的查询 token 数据,但会将其与不同的键 token 数据相乘。
const scalar_t* q_ptr = q + seq_idx * q_stride + head_idx * HEAD_SIZE;
 一个头中的一个 token 的查询数据
一个头中的一个 token 的查询数据
- 每个线程定义自己的
q_ptr,它指向全局内存上分配的查询 token 数据。例如,如果VEC_SIZE为 4,HEAD_SIZE为 128,则q_ptr指向包含总共 128 个元素的数据,分为 128 / 4 = 32 个向量。
 一个线程组中的
一个线程组中的 q_vecs
__shared__ Q_vec q_vecs[THREAD_GROUP_SIZE][NUM_VECS_PER_THREAD];
- 接下来,我们需要将
q_ptr指向的全局内存数据读取到共享内存中作为q_vecs。需要注意的是,每个 vec 都被分配到不同的行。例如,如果THREAD_GROUP_SIZE为2,则线程 0 将处理第 0 行 vec,而线程1处理第1行 vec。通过这种方式读取查询数据,线程0和线程1等相邻线程可以读取相邻内存,实现内存合并以提高性能。
Key
- 与「查询」部分类似,本部分介绍内存布局和键的分配。虽然每个线程组在一个内核运行时仅处理一个查询 token ,但它可以在多次迭代中处理多个键 token 。同时,每个 warp 将在多次迭代中处理多个键 token 块,确保内核运行后所有上下文 token 都由整个线程组处理。在本文中,「处理」是指执行查询数据和键数据之间的点乘。
const scalar_t* k_ptr = k_cache + physical_block_number * kv_block_stride
+ kv_head_idx * kv_head_stride
+ physical_block_offset * x;
- 与
q_ptr不同,每个线程中的k_ptr将在不同迭代中指向不同的键 token。如上所示,k_ptr指向分配块、分配头和分配 token 处基于k_cache的键 token 数据。
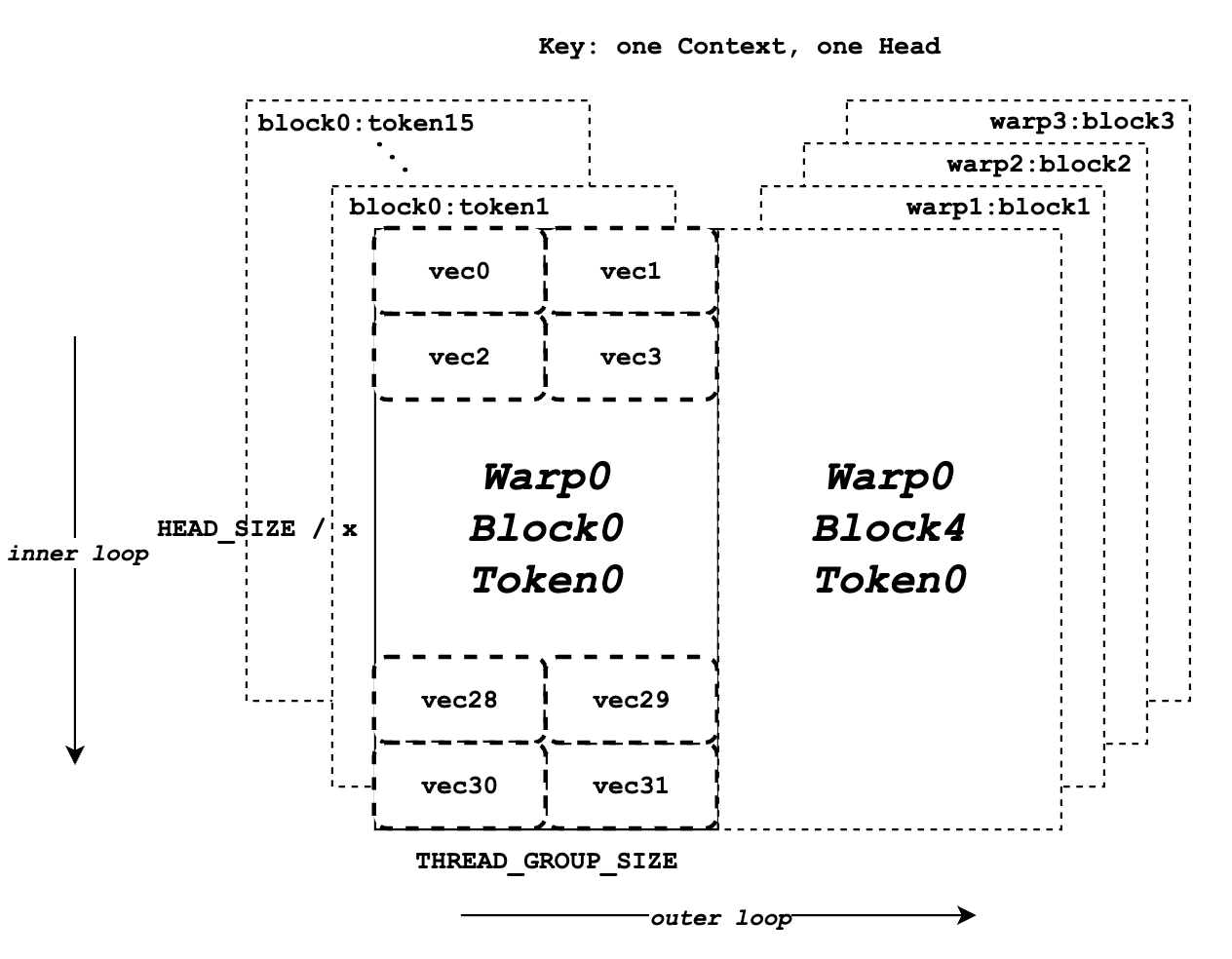 一个头中的所有上下文 token 的键数据
一个头中的所有上下文 token 的键数据
- 上图说明了键数据的内存布局。假设
BLOCK_SIZE为 16,HEAD_SIZE为 128,x为 8,THREAD_GROUP_SIZE为 2,总共有 4 个 warp。每个矩形代表一个头部的一个键 token 的所有元素,这些元素将由一个线程组处理。左半部分显示了 warp 0 的总共 16 个键 token 数据块,而右半部分表示其他 warp 或迭代的剩余键 token 数据。每个矩形内部共有 32 个 vec(一个 token 128 个元素),将分别由 2 个线程(一个线程组)处理。
 一个线程组中的
一个线程组中的 q_vecs
K_vec k_vecs[NUM_VECS_PER_THREAD]
-
接下来,我们需要从
k_ptr读取键 token 数据并将它们存储在寄存器内存中作为k_vecs。我们对k_vecs使用寄存器内存,因为它只能被一个线程访问一次,而q_vecs将被多个线程多次访问。每个k_vecs将包含多个向量以供后续计算。每个 vec 将在每次内部迭代时设置。 vec 的分配允许 warp 中的相邻线程一起读取相邻内存,这再次促进了内存合并。例如,线程 0 将读取 vec 0,而线程 1 将读取 vec 1。在下一个内循环中,线程 0 将读取 vec 2,而线程 1 将读取 vec 3,依此类推。 -
您可能对整体流程仍然有点困惑。别担心,请继续阅读下一节「QK」部分。它将以更清晰、更高层次的方式说明查询和键计算流程。
QK
- 如下面的伪代码所示,在整个 for 循环块之前,我们获取一个 token 的查询数据并将其存储在
q_vecs中。然后,在外部 for 循环中,我们迭代指向不同 token 的不同k_ptrs,并在内部 for 循环中准备k_vecs。最后,我们在q_vecs和每个k_vecs之间执行点乘。
q_vecs = ...
for ... {
k_ptr = ...
for ... {
k_vecs[i] = ...
}
...
float qk = scale * Qk_dot<scalar_t, THREAD_GROUP_SIZE>::dot(q_vecs[thread_group_offset], k_vecs);
}
-
如前所述,对于每个线程,它一次仅获取部分查询和键 token 数据。然而,在
Qk_dot<>::dot中将会发生跨线程组减少。因此,这里返回的qk不仅仅是部分查询和键 token 之间点乘的结果,实际上是整个查询和键 token 数据之间的完整结果。 -
例如,如果
HEAD_SIZE的值为 128,THREAD_GROUP_SIZE为 2,则每个线程的k_vecs总共将包含 64 个元素。然而,返回的 qk 实际上是 128 个查询元素和 128 个键元素点乘的结果。如果你想了解更多关于点乘和减少的细节,可以参考Qk_dot<>::dot的实现。不过,为了简单起见,不会在本文档中介绍它。
Softmax
- 接下来,我们需要计算所有
qk的归一化 softmax,如上所示,其中每个 代表一个qk。为此,我们必须获得所有qk的qk_max() 和exp_sum() 的减少值。减少应该在整个线程块上执行,包括查询 token 和所有上下文键 token 之间的结果。
qk_max 和 logits
- 得到
qk结果后,我们可以用qk设置临时logits结果 (最后,logits应该存储归一化的 softmax 结果)。我们还可以比较并收集当前线程组计算的所有qk的qk_max。
if (thread_group_offset == 0) {
const bool mask = token_idx >= context_len;
logits[token_idx - start_token_idx] = mask ? 0.f : qk;
qk_max = mask ? qk_max : fmaxf(qk_max, qk);
}
- 请注意,这里的
logits位于共享内存上,因此每个线程组将为自己分配的上下文 token 设置字段。总的来说,logits 的大小应该是上下文 token 的数量。
for (int mask = WARP_SIZE / 2; mask >= THREAD_GROUP_SIZE; mask /= 2) {
qk_max = fmaxf(qk_max, VLLM_SHFL_XOR_SYNC(qk_max, mask));
}
if (lane == 0) {
red_smem[warp_idx] = qk_max;
}
- 然后我们需要获得每个 warp 上减少的
qk_max。主要思想是让 warp 中的线程相互通信并获得最终的qk最大值 。
for (int mask = NUM_WARPS / 2; mask >= 1; mask /= 2) {
qk_max = fmaxf(qk_max, VLLM_SHFL_XOR_SYNC(qk_max, mask));
}
qk_max = VLLM_SHFL_SYNC(qk_max, 0);
- 最后,通过比较该线程块中所有 warp 的
qk_max,我们可以得到整个线程块减少的qk_max。然后将最终结果广播到每个线程。
exp_sum
- 与
qk_max类似,我们也需要从整个线程块中获取减少的总和值。
for (int i = thread_idx; i < num_tokens; i += NUM_THREADS) {
float val = __expf(logits[i] - qk_max);
logits[i] = val;
exp_sum += val;
}
...
exp_sum = block_sum<NUM_WARPS>(&red_smem[NUM_WARPS], exp_sum);
- 首先,对每个线程组的所有 exp 值求和,同时将
logits的每个条目从qk转换为exp(qk - qk_max)。请注意,这里的qk_max已经是整个线程块的最大qk。然后我们可以像qk_max一样在整个线程块上减少exp_sum。
const float inv_sum = __fdividef(1.f, exp_sum + 1e-6f);
for (int i = thread_idx; i < num_tokens; i += NUM_THREADS) {
logits[i] *= inv_sum;
}
- 最后,通过减少
qk_max和exp_sum,我们可以获得最终的归一化 softmax 结果,即logits。这个logits变量将在后面的步骤中用于与值数据进行点乘。现在,它应该存储所有分配的上下文 token 的qk的标准化 softmax 结果。
值
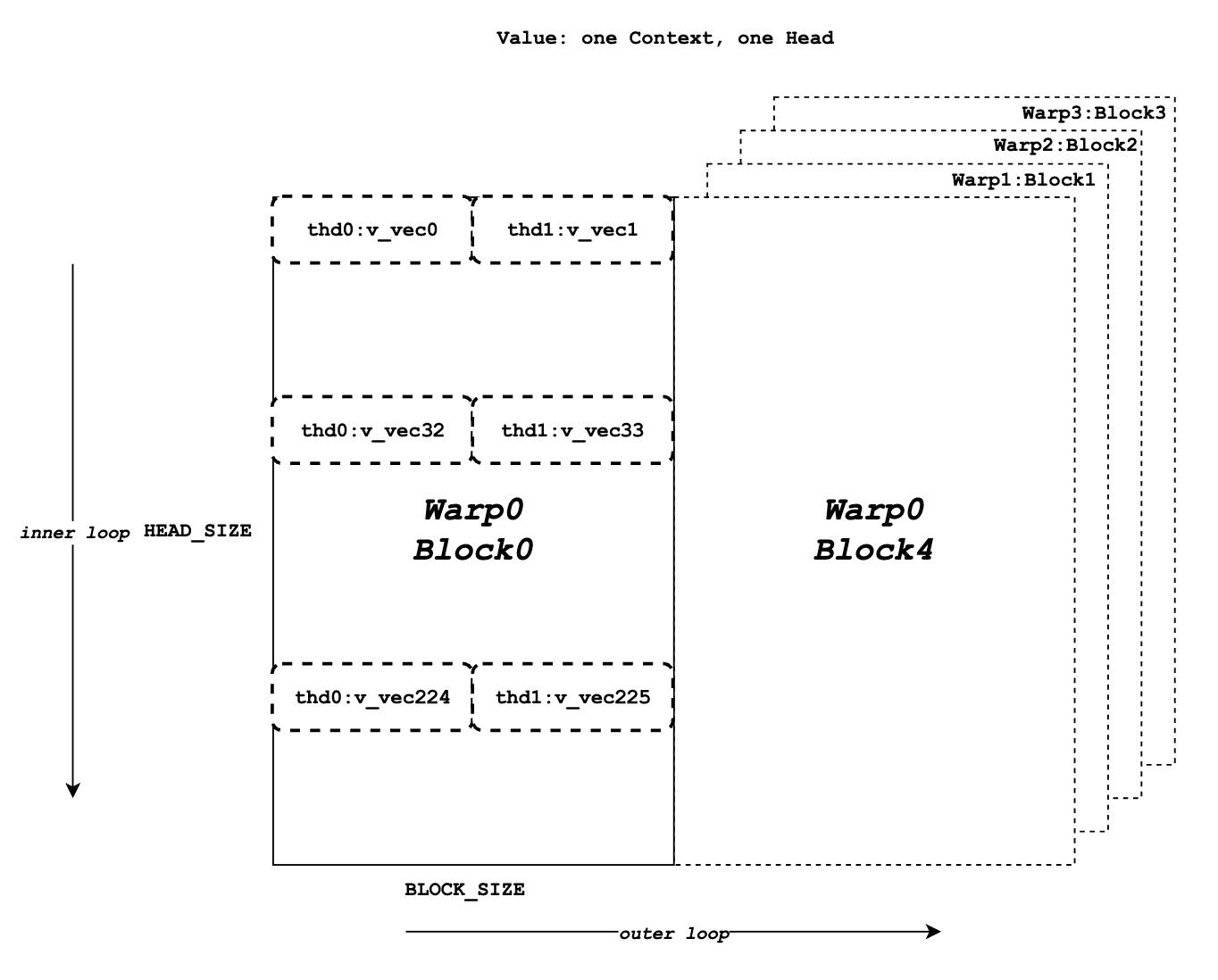
一个头中全部上下文 token 的值数据

一个线程中的 logits_vec
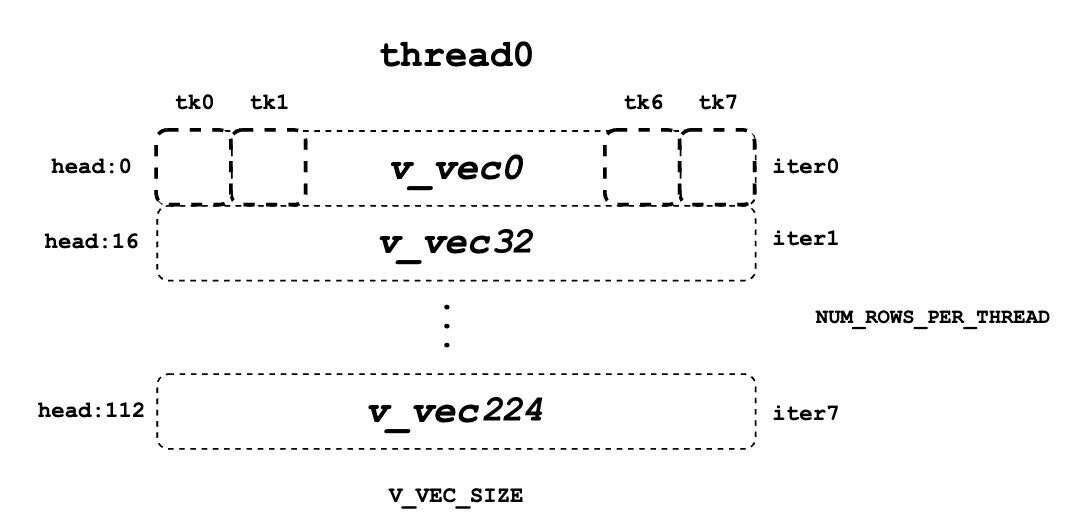
一个线程中的 v_vec 列表
-
现在我们需要检索值数据并与
logits进行点乘。与查询和键不同,值数据没有线程组概念。如图所示,与键 token 内存布局不同,同一列的元素对应于相同的值 token 。对于一个值数据块,行有HEAD_SIZE,列有BLOCK_SIZE,它们被分割成多个v_vec。 -
每个线程始终一次从
V_VEC_SIZE个 token 中获取一样多的V_VEC_SIZE个元素。因此,单个线程通过多次内部迭代从不同的行和相同的列检索多个v_vec。对于每个v_vec,它需要与相应的logits_vec进行点乘,后者也是来自logits的V_VEC_SIZE个元素。总体而言,通过多次内部迭代,每个 warp 将处理一个块的值 token;而通过多次外部迭代,整个上下文的值 token 被处理。
float accs[NUM_ROWS_PER_THREAD];
for ... { // Iteration over different blocks. // 在不同块上迭代
logits_vec = ...
for ... { // Iteration over different rows. // 在不同行上迭代
v_vec = ...
...
accs[i] += dot(logits_vec, v_vec);
}
}
-
如上面的伪代码所示,在外层循环中,
logits_vec类似于k_ptr,遍历不同的块并从logits中读取V_VEC_SIZE个元素。在内层循环中,每个线程从相同的 token 中读取V_VEC_SIZE个元素作为v_vec并进行点乘。需要注意的是,在每次内部迭代中,线程为相同的 token 获取不同头位置的元素。点乘结果随后被累加到accs中。因此,accs的每个条目映射到分配给当前线程的头位置。 -
例如,如果
BLOCK_SIZE为 16,V_VEC_SIZE为 8,则每个线程一次为 8 个 token 获取 8 个值元素。每个元素都来自同一头位置的不同 token 。如果HEAD_SIZE为 128,WARP_SIZE为 32,则对于每个内部循环, warp 需要获取WARP_SIZE * V_VEC_SIZE = 256元素。这意味着 warp 总共需要 128 * 16 / 256 = 8 次内部迭代来处理整个值 token 块。每个线程中的每个 accs 包含 8 个元素,这些元素累积在 8 个不同的头位置。对于线程 0,accs变量将有 8 个元素,它们是从所有分配的 8 个 token 中累积的值头的第 0 个、第 32 个……第 224 个元素。
LV
- 现在,我们需要在每个 warp 内对
accs进行缩减。这一过程允许每个线程为一个块中所有 token 的指定头位置累积accs。
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
float acc = accs[i];
for (int mask = NUM_V_VECS_PER_ROW / 2; mask >= 1; mask /= 2) {
acc += VLLM_SHFL_XOR_SYNC(acc, mask);
}
accs[i] = acc;
}
- 接下来,我们对所有 warp 执行
accs缩减,允许每个线程为所有上下文 token 的指定头位置积累accs。请注意,每个线程中的每个accs仅存储所有上下文 token 的整个头的部分元素的累加。然而,总体而言,所有输出结果都已经计算出来,只是存储在不同的线程寄存器存储器中。
float* out_smem = reinterpret_cast<float*>(shared_mem);
for (int i = NUM_WARPS; i > 1; i /= 2) {
// 上面的 warp 写入共享内存
...
float* dst = &out_smem[(warp_idx - mid) * HEAD_SIZE];
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
...
dst[row_idx] = accs[i];
}
// 底下的 warp 更新输出
const float* src = &out_smem[warp_idx * HEAD_SIZE];
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
...
accs[i] += src[row_idx];
}
// 写出 accs
}
输出
- 现在我们可以将所有计算结果从本地寄存器内存写入最终输出的全局内存。
scalar_t* out_ptr = out + seq_idx * num_heads * max_num_partitions * HEAD_SIZE
+ head_idx * max_num_partitions * HEAD_SIZE
+ partition_idx * HEAD_SIZE;
- 首先,我们需要定义
out_ptr变量,它指向分配序列和分配头的起始地址。
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE && lane % NUM_V_VECS_PER_ROW == 0) {
from_float(*(out_ptr + row_idx), accs[i]);
}
}
- 最后,我们需要遍历不同分配的头位置,并根据
out_ptr写出相应的累积结果。