自动前缀缓存
前缀缓存 KV 缓存块是 LLM 推理中一种流行的优化技术,用于避免冗余的提示计算。核心思想很简单——我们缓存已处理请求的 KV 缓存块,当新请求到来时如果前缀与之前请求相同就重用这些块。由于前缀缓存几乎是无成本的且不会改变模型输出,它已被许多公共端点(如 OpenAI、Anthropic 等)和大多数开源 LLM 推理框架(如 SGLang)广泛采用。
虽然实现前缀缓存有多种方式,vLLM 选择了基于哈希的方法。具体来说,我们通过块中的 token 和块之前的前缀 token 对每个 KV 缓存块进行哈希:
Block 1 Block 2 Block 3
[A gentle breeze stirred] [the leaves as children] [laughed in the distance]
Block 1: |<--- block tokens ---->|
Block 2: |<------- prefix ------>| |<--- block tokens --->|
Block 3: |<------------------ prefix -------------------->| |<--- block tokens ---->|
在上面的例子中,第一个块的 KV 缓存可以用t oken "A gentle breeze stirred" 唯一标识。第三个块可以用块中的 token "laughed in the distance" 加上前缀 token "A gentle breeze stirred the leaves as children" 唯一标识。因此我们可以构建块哈希 hash(tuple[components]),其中 components 包括:
-
父哈希值:父哈希块的哈希值
-
块 token:该块中 token 的元组。包含确切 token 是为了减少潜在的哈希值冲突
-
额外哈希:使该块唯一所需的其他值,如 LoRA ID 和多模态输入哈希(见下例)
注意1:我们只缓存完整的块。 注意2:上述哈希键结构并非 100% 无冲突。理论上不同前缀 token 仍可能有相同的哈希值。为避免多租户设置中的任何哈希冲突,建议使用 SHA256 作为哈希函数而非默认的内置哈希。SHA256 自 vLLM v0.8.3 起支持,必须通过命令行参数启用。它会对每个 token 带来约 100-200ns 的性能影响(对于 50k token 的上下文约 6ms)。
多模态输入的哈希示例
这个例子展示了前缀缓存如何处理多模态输入(如图像)。假设我们有以下消息的请求:
messages = [
{"role": "user",
"content": [
{"type": "text",
"text": "What's in this image?"
},
{"type": "image_url",
"image_url": {"url": image_url},
},
]},
]
它将变成以下提示:
Prompt:
<s>[INST]What's in this image?\n[IMG][/INST]
Tokenized prompt:
[1, 3, 7493, 1681, 1294, 1593, 3937, 9551, 10, 4]
Prompt with placeholders (<P>):
[1, 3, 7493, 1681, 1294, 1593, 3937, 9551, <P>, <P>, ..., <P>, 4]
可以看到,在 token 化后,[IMG]将被一系列占位符token替换,这些占位符将在预填充阶段被图像嵌入替换。前缀缓存支持这种情况的挑战是需要区分图像和占位符。为解决这个问题,我们编码由前端图像处理器生成的图像哈希。例如上述提示中块的哈希将是(假设块大小为 16,我们有 41 个占位符 token):
Block 0
Parent hash: None
Token IDs: 1, 3, 7493, 1681, 1294, 1593, 3937, 9551, <p>, ..., <p>
Extra hash: <image hash>
Block 1
Parent hash: Block 0 hash
Token IDs: <p>, ..., <p>
Extra hash: <image hash>
Block 2
Parent hash: Block 1 hash
Token IDs: <p>, ..., <p>
Extra hash: <image hash>
Block 3
Parent hash: Block 2 hash
Token IDs: <p>, ..., <p>, 4
Extra hash: <image hash>
在本文档后续内容中,我们将首先介绍 vLLM v1 版本中用于前缀缓存的数据结构,接着详细说明 KV 缓存主要操作(包括分配、追加、释放和淘汰)的前缀缓存工作流程。最后,我们将通过一个完整示例来展示端到端的前缀缓存工作流程。
数据结构
vLLM v1 的前缀缓存实现在 KV 缓存管理器中,其基本构建单元是简化的「Block」数据类:
class KVCacheBlock:
# The block ID (immutable)
# 块 ID(不可变)
block_id: int
# The block hash (will be assigned when the block is full,
# and will be reset when the block is evicted).
# 块哈希值(当块填满时赋值,块被驱逐时重置)
block_hash: BlockHashType
# The number of requests using this block now.
# 当前使用该块的请求数量
ref_cnt: int
# The pointers to form a doubly linked list for the free queue.
# 用于构建自由队列的双向链表指针
prev_free_block: Optional["KVCacheBlock"] = None
next_free_block: Optional["KVCacheBlock"] = None
有两处关键设计要点
-
我们在初始化 KV 缓存管理器时,会预先分配所有的 KVCacheBlock 形成块池。这样既避免了 Python 对象创建带来的性能开销,又可以持续追踪所有块的状态。
-
通过在 KVCacheBlock 中直接嵌入双向链表指针,可以直接构造一个空闲队列,这带来了双重优势:
-
支持 O(1) 复杂度将队列中间元素快速移至队尾
-
无需引入其他 Python 队列结构(如 deque)及其带来的元素封装层
-
因此,KV 缓存管理器初始化后将包含以下组件:
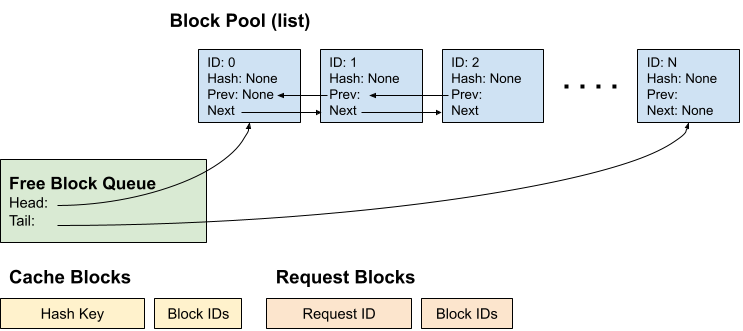
-
**Block Pool:**KVCacheBlock 的列表。
-
自由块队列:仅存储头尾块指针用于操作
-
缓存块:哈希键到块 ID 的映射
-
请求块:请求 ID 到已分配块 ID 的映射
操作
块分配
**新请求:**调度器为包含 KV 缓存块分配的新请求进行调度的流程:
-
调度器调用
kv_cache_manager.get_computed_blocks()获取已计算块的序列。该操作通过哈希请求的提示 token 并查询缓存块实现。 -
调度器调用
kv_cache_manager.allocate_slots(),执行以下步骤:-
计算所需新块数量,若可用块不足则立即返回
-
「触碰」已计算块。它将已计算块的引用计数加一。若该块未被其他请求使用,则从自由队列移除该块(防止这些已计算块被驱逐,详见下节示例)
-
分配新块:通过弹出自由队列头部块实现。若头部块是缓存块,则执行"驱逐"操作使该块无法被后续请求复用
-
缓存填满块:若分配的块已完全填充 token,立即将其加入缓存块以便同批次其他请求复用
-
**运行中请求:**调度器为运行中请求分配 KV 缓存块的流程:
-
调度器调用
kv_cache_manager.append_slots(),执行以下步骤:-
计算所需新块数量,若可用块不足则立即返回
-
分配新块:通过弹出自由队列头部块实现。若头部块是缓存块,则执行驱逐操作
-
追加 token:将 token ID 追加到现有块和新块的槽位。若某块填满 token,则将其加入缓存块
-
重复块现象
假设块大小为 4,发送请求 1(提示 ABCDEF,解码长度 3):
Prompt: [A, B, C, D, E, F]
Output: [G, H, I]
Time 0:
Tokens: [A, B, C, D, E, F, G]
Block Table: [0 (ABCD), 1 (EFG)]
Cache Blocks: 0
Time 1:
Tokens: [A, B, C, D, E, F, G, H]
Block Table: [0 (ABCD), 1 (EFGH)]
Cache Blocks: 0, 1
Time 2:
Tokens: [A, B, C, D, E, F, G, H, I]
Block Table: [0 (ABCD), 1 (EFGH), 2 (I)]
Cache Blocks: 0, 1
当块 0 和块 1 已缓存后,再次发送相同请求(请求 2)并使用贪婪采样,该请求将产生与请求 1 完全相同的输出:
Prompt: [A, B, C, D, E, F]
Output: [G, H, I]
Time 0:
Tokens: [A, B, C, D, E, F, G]
Block Table: [0 (ABCD), 3 (EFG)]
Cache Blocks: 0, 1
Time 1:
Tokens: [A, B, C, D, E, F, G, H]
Block Table: [0 (ABCD), 3 (EFGH)]
Cache Blocks: 0, 1, 3
可以看到,块 3 是一个新的完整块,并且已被缓存。然而,它与块 1 是冗余的,这意味着我们缓存了相同的块两次。在 v0 版本中,当检测到块 3 是重复的时,我们会释放块 3,并让请求 2 使用块 1,因此在时间点 1,它的块表变为 [0, 1]。然而,在 vLLM v1 版本中,块表是追加式的(append-only),这意味着无法将块表从 [0, 3] 更改为 [0, 1]。因此,对于哈希键 E-H,我们会有重复的块。这种重复会在请求被释放时被消除。
释放
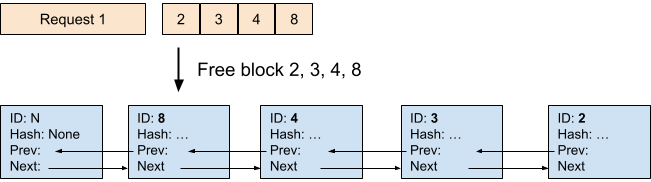
当一个请求完成时,如果没有其他请求正在使用它的块(引用计数 = 0),我们就会释放这些块。在本示例中,我们释放了请求 1 及其关联的块 2、3、4 和 8。可以看到,被释放的块按照逆序添加到了空闲队列的尾部。这是因为请求的最后一个块通常会哈希更多的 token,因此不太可能被其他请求复用。因此,它应该被优先驱逐 (evicted)。
驱逐 (LRU)
当空闲队列的头部块(即最近最少使用的块)已被缓存时,我们必须将其驱逐,以防止其他请求继续使用它。具体的驱逐步骤如下:
-
从空闲队列的头部弹出一个块(这是要驱逐的 LRU 块)。
-
从缓存块表(Cache Block)中移除该块的 ID。
-
移除该块的哈希。
示例
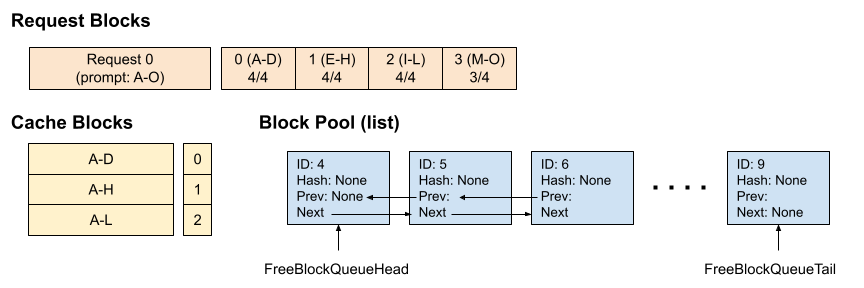
假设每个块的大小为 4(即每个块可以缓存 4 个 token),KV 缓存管理器总共有 10 个块。
时间点 1:缓存为空,一个新请求到来,我们分配了 4 个块。其中 3 个块已满并被缓存,第 4 个块部分填充了 3/4 个 token。
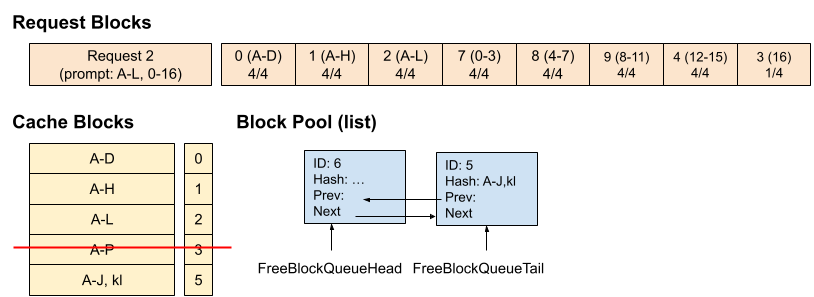
**时间点 3:请求 0 填满了块 3,并请求新的块以继续解码。**我们缓存块 3,并分配块 4。
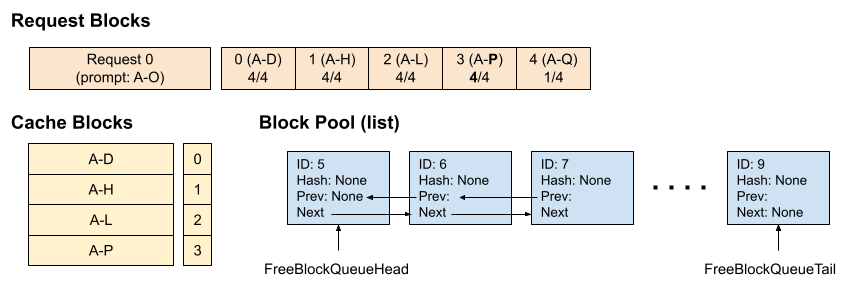
时间点 4 : 请求 1 进入,并带有 14 个 prompt token,其中前 10 个 token 与请求 0 相同。 仅前 2 个块(8 个 token)命中缓存,因为第 3 个块仅匹配 2/4 个 token。
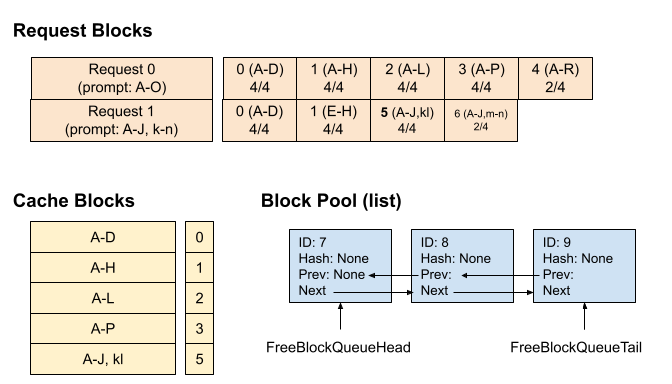
时间点 5:请求 0 结束并释放,块 2、3 和 4 以逆序添加到空闲队列(但块 2 和 3 仍被缓存)。 块 0 和 1 未被添加到空闲队列,因为请求 1 仍在使用它们。
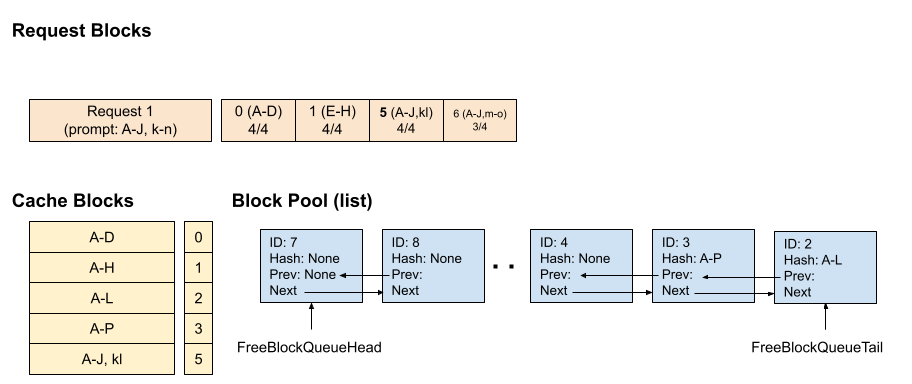
**时间点 6 :**请求 1 结束并释放。
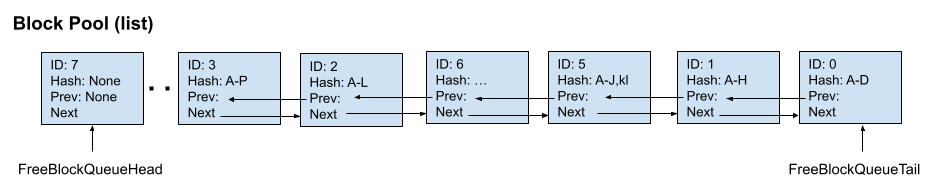
时间点 7:请求 2 进入,并带有 29 个 prompt token,其中前 12 个 token 与请求 0 相同。 虽然空闲队列的顺序是 7 - 8 - 9 - 4 - 3 - 2 - 6 - 5 - 1 - 0,但由于缓存命中的块(0、1、2)在分配前会被移除,最终的空闲队列变为7 - 8 - 9 - 4 - 3 - 6 - 5。 因此,分配的块为 0(缓存命中)、1(缓存命中)、2(缓存命中)、7、8、9、4、3(被驱逐)。