指标
确保 v1 LLM 引擎公开的指标是 v0 可用指标的超集。
目标
-
在 v0 和 v1 之间实现指标的对等。
-
主要使用场景是通过 Prometheus 访问这些指标,因为这预计将在生产环境中使用。
-
支持日志记录——即将指标打印到信息日志——用于更临时的测试、调试、开发和探索性用途。
背景
vLLM 中的指标可分为以下几类:
-
服务器级指标:这些是跟踪 LLM 引擎状态和性能的全局指标。通常在 Prometheus 中以 Gauges 或 Counters 公开。
-
请求级指标:这些指标跟踪单个请求的特征,例如大小和时间。通常在 Prometheus 中以 Histograms 公开,并且通常是 SRE 监控 vLLM 时关注的 SLO(服务级目标)。
心智模型是「服务器级指标」解释「请求级指标」为什么会是当前的状态。
v0 指标
在 v0 版本中,以下指标通过 Prometheus 兼容的 /metrics 端点暴露,使用 vllm: 作为前缀:
-
vllm:num_requests_running(Gauge) -
vllm:num_requests_swapped(Gauge) -
vllm:num_requests_waiting(Gauge) -
vllm:gpu_cache_usage_perc(Gauge) -
vllm:cpu_cache_usage_perc(Gauge) -
vllm:gpu_prefix_cache_hit_rate(Gauge) -
vllm:cpu_prefix_cache_hit_rate(Gauge) -
vllm:prompt_tokens_total(Counter) -
vllm:generation_tokens_total(Counter) -
vllm:request_success_total(Counter) -
vllm:request_prompt_tokens(Histogram) -
vllm:request_generation_tokens(Histogram) -
vllm:time_to_first_token_seconds(Histogram) -
vllm:time_per_output_token_seconds(Histogram) -
vllm:e2e_request_latency_seconds(Histogram) -
vllm:request_queue_time_seconds(Histogram) -
vllm:request_inference_time_seconds(Histogram) -
vllm:request_prefill_time_seconds(Histogram) -
vllm:request_decode_time_seconds(Histogram) -
vllm:request_max_num_generation_tokens(Histogram) -
vllm:num_preemptions_total(Counter) -
vllm:cache_config_info(Gauge) -
vllm:lora_requests_info(Gauge) -
vllm:tokens_total(Counter) -
vllm:iteration_tokens_total(Histogram) -
vllm:time_in_queue_requests(Histogram) -
vllm:model_forward_time_milliseconds(Histogram) -
vllm:model_execute_time_milliseconds(Histogram) -
vllm:request_params_n(Histogram) -
vllm:request_params_max_tokens(Histogram) -
vllm:spec_decode_draft_acceptance_rate(Gauge) -
vllm:spec_decode_efficiency(Gauge) -
vllm:spec_decode_num_accepted_tokens_total(Counter) -
vllm:spec_decode_num_draft_tokens_total(Counter) -
vllm:spec_decode_num_emitted_tokens_total(Counter)
这些指标的文档可在 Inferencing and Serving -> Production Metrics 中找到。
Grafana 仪表盘
vLLM 还提供了参考示例,展示如何使用 Prometheus 收集和存储这些指标,并在 Grafana 仪表盘中可视化。
Grafana 仪表盘中公开的指标子集表明了哪些指标特别重要:
-
vllm:e2e_request_latency_seconds_bucket- 端到端请求延迟(秒) -
vllm:prompt_tokens_total- 每秒提示词 token 数 -
vllm:generation_tokens_total- 每秒生成 token 数 -
vllm:time_per_output_token_seconds-token间延迟(每个输出token时间,TPOT) -
vllm:time_to_first_token_seconds- 第一个token的时间 (TTFT) 延迟 -
vllm:num_requests_running(以及_swapped和_waiting)- 运行中、等待中和交换中的请求数 -
vllm:gpu_cache_usage_perc- vLLM 使用的缓存块百分比 -
vllm:request_prompt_tokens- 请求提示词长度 -
vllm:request_generation_tokens- 请求生成长度 -
vllm:request_success_total- 以完成原因分类的请求数量(例如,生成了 EOS token 或达到最大序列长度) -
vllm:request_queue_time_seconds- 队列时间 -
vllm:request_prefill_time_seconds- 请求预填充时间 -
vllm:request_decode_time_seconds- 请求解码时间 -
vllm:request_max_num_generation_tokens- 序列组中的最大生成token数
更多关于仪表盘设计的背景信息,可参阅添加此仪表盘的 PR。
Prometheus 客户端库
最初,Prometheus 支持是使用 aioprometheus 库添加的,但很快就切换到了 prometheus_client。相关讨论可见于上述 PR。
多进程模式
在 v0 版本中,指标是在引擎核心进程中收集的,并使用多进程模式使其在 API 服务器进程中可用。详见 Pull Request #7279。
内置 Python/进程指标
prometheus_client 默认支持以下指标,但在使用多进程模式时不会公开:
-
python_gc_objects_collected_total -
python_gc_objects_uncollectable_total -
python_gc_collections_total -
python_info -
process_virtual_memory_bytes -
process_resident_memory_bytes -
process_start_time_seconds -
process_cpu_seconds_total -
process_open_fds -
process_max_fds
这与 v1 可能相关,因为如果我们在 v1 版本中放弃多进程模式,这些指标将会重新可用。但如果它们不能聚合所有进程的数据,那么其相关性可能存疑。
v0 相关 PR 和问题
以下是一些添加 v0 指标的相关 PR:
此外,还可以关注“更好的可观测性”功能,例如,详细的路线图已经在相关讨论中列出。
v1 设计
v1 相关 PR
为了提供背景信息,以下是与 v1 版本指标( Issue #10582)相关的 PR:
指标收集
在 v1 版本中,我们希望将计算和开销移出引擎核心进程,以尽量减少每次前向传播之间的时间间隔。
v1 版 EngineCore 设计的整体思路是:
-
EngineCore 是核心循环,其性能最为关键。
-
AsyncLLM 是外部循环,它应与 GPU 执行并行(理想情况下),因此所有“额外开销”尽可能放在这里。因此,
AsyncLLM.output_handler_loop是最理想的指标记录位置。
我们将通过在前端 API 服务器收集指标来实现这一点,并且这些指标基于 EngineCoreOutputs 中的信息,该信息由引擎核心进程返回给前端。
时间间隔计算
许多指标都是基于处理请求的各个事件之间的时间间隔。计算时间间隔的最佳实践是使用 单调时间(time.monotonic())而不是 壁钟时间(time.time()),因为前者不受系统时钟调整(例如 NTP 同步)的影响。
需要注意的是,单调时钟在不同进程之间是独立的,每个进程都有自己的参考点。因此,不能直接比较不同进程中的单调时间戳。
因此,为了计算时间间隔,我们必须比较来自同一进程的两个单调时间戳。
调度器统计信息
引擎核心进程将从调度器中收集一些关键统计数据,例如:在上一次调度器运行后,被调度或仍在等待的请求数量。
这些统计信息将包含在 EngineCoreOutputs 中。
引擎核心事件
引擎核心将记录某些与请求相关的事件时间戳,以便前端计算这些事件之间的时间间隔。
这些事件包括:
-
QUEUED:请求被引擎核心接收并加入调度队列时。 -
SCHEDULED:请求首次被调度执行时。 -
PREEMPTED:请求被重新放入等待队列,以便腾出资源让其他请求完成,之后会重新调度并重新开始预填充阶段。 -
NEW_TOKENS:当EngineCoreOutput生成新 token 时,由于同一批请求共享相同的时间戳,因此我们在EngineCoreOutputs上记录这个事件。
计算的时间间隔包括:
-
排队间隔:
QUEUED到最近的SCHEDULED之间的时间。 -
预填充间隔:最近的
SCHEDULED到第一个NEW_TOKENS之间的时间。 -
解码间隔:从
SCHEDULED之后的第一个NEW_TOKENS到最后一个NEW_TOKENS之间的时间。 -
推理间隔:最近的
SCHEDULED到最后一个NEW_TOKENS之间的时间。 -
Token 间隔:连续
NEW_TOKENS之间的时间。
换句话说:
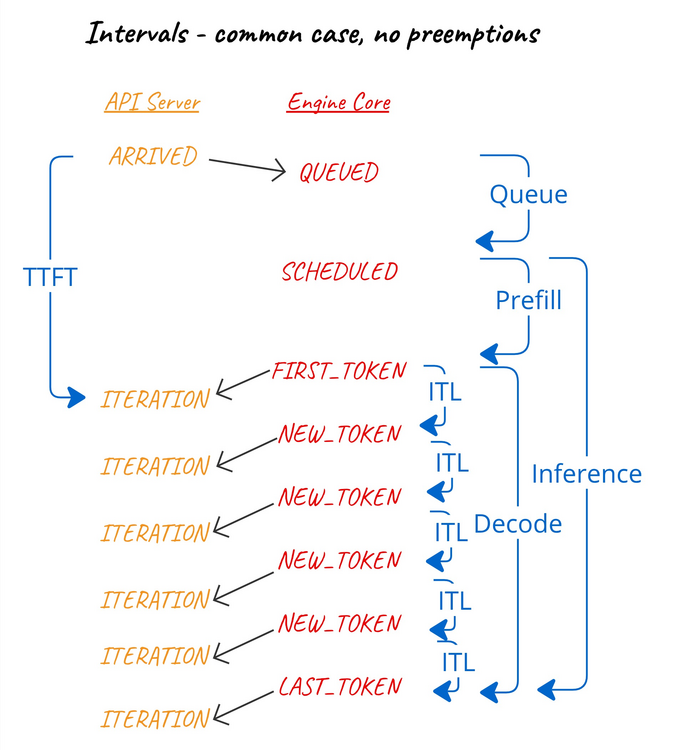
我们曾探索过让前端通过可见事件的时间来计算这些时间间隔的可能性。然而,前端无法获取 QUEUED 和 SCHEDULED 事件的时间信息,并且由于我们需要基于同一进程中的单调时间戳来计算时间间隔,因此必须由引擎核心记录所有这些事件的时间戳。
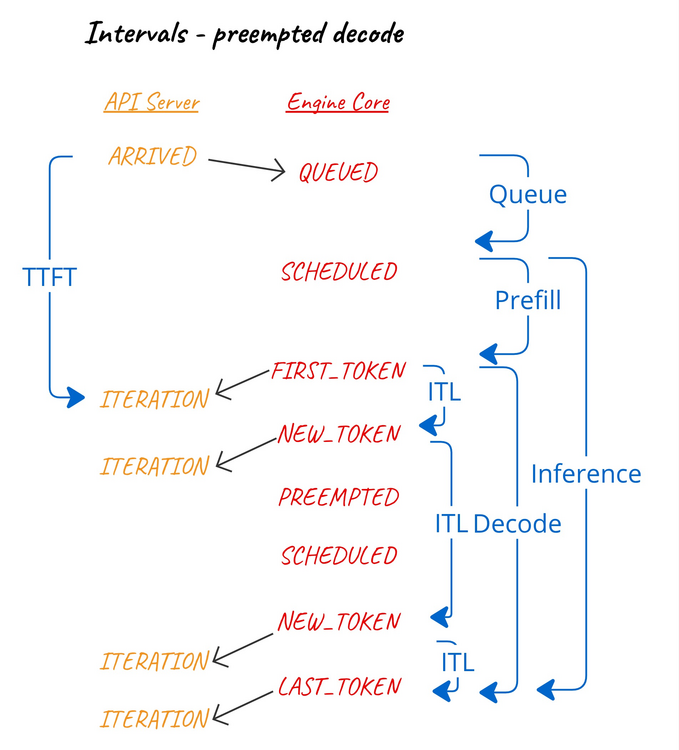
时间间隔计算与抢占
当解码过程中发生抢占时,由于已生成的 token 会被重用,因此抢占会影响 token 间隔、解码间隔和推理间隔。
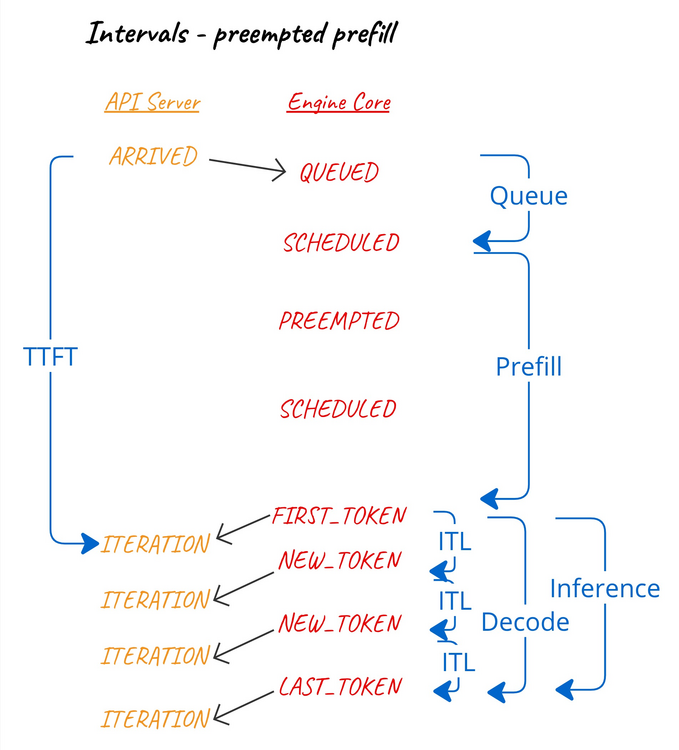
 当预填充阶段发生抢占(假设这种情况可能发生)时,我们认为该抢占会影响首个 token 生成时间和预填充时间间隔。
当预填充阶段发生抢占(假设这种情况可能发生)时,我们认为该抢占会影响首个 token 生成时间和预填充时间间隔。
前端统计收集
前端在处理单个 EngineCoreOutputs(即引擎核心一次迭代的输出)时,将收集与该迭代相关的各种统计信息,包括:
-
本次迭代生成的新 token 总数。
-
本次迭代完成预填充的 prompt token 总数。
-
本次迭代中被调度的请求的排队间隔。
-
本次迭代完成预填充的请求的预填充间隔。
-
所有请求的 token 间隔(输出 token 时间,TPOT)。
-
本次迭代完成预填充的请求的 首 token 响应时间 (TTFT),但该间隔相对于前端最初接收到请求的
arrival_time计算,以考虑输入处理时间。
对于在某次迭代中完成的请求,还将记录:
-
推理间隔和解码间隔(相对于
SCHEDULED和NEW_TOKENS事件)。 -
端到端延迟(从
arrival_time到前端接收到最后一个 token 之间的时间)。
指标发布 - 日志记录
LoggingStatLogger 指标发布器每 5 秒记录一次 INFO 日志,包含以下关键指标:
-
当前运行/等待的请求数
-
当前 GPU 缓存使用情况
-
过去 5 秒处理的 prompt token 数
-
过去 5 秒生成的新 token 数
-
最近 1000 个 KV-cache 块查询的前缀缓存命中率
指标发布 - Prometheus
PrometheusStatLogger 指标发布器通过 /metrics HTTP 端点提供 Prometheus 兼容的指标。Prometheus 可配置为每秒轮询该端点,并将数据存入时间序列数据库。Prometheus 通常与 Grafana 一起使用,以可视化指标数据。
Prometheus 支持以下指标类型:
-
计数器 (Counter):值只增不减,通常在 vLLM 实例重启时重置。例如,实例生命周期内生成的 token 数量。
-
仪表 (Gauge):值可以增加或减少,例如当前正在执行的请求数。
-
直方图 (Histogram):以桶 (buckets) 的方式记录指标样本数。例如,TTFT 在 <1ms, <5ms, <10ms, <20ms 等范围内的请求数。
Prometheus 指标可以带标签,以便按标签进行聚合。在 vLLM 中,我们给每个指标添加 model_name 标签,以指示该实例提供的模型名称。
示例输出:
$ curl http://0.0.0.0:8000/metrics
# HELP vllm:num_requests_running Number of requests in model execution batches. 模型执行批次中正在运行的请求数量。
# TYPE vllm:num_requests_running gauge
vllm:num_requests_running{model_name="meta-llama/Llama-3.1-8B-Instruct"} 8.0
...
# HELP vllm:generation_tokens_total Number of generation tokens processed.已处理的生成 token 总数。
# TYPE vllm:generation_tokens_total counter
vllm:generation_tokens_total{model_name="meta-llama/Llama-3.1-8B-Instruct"} 27453.0
...
# HELP vllm:request_success_total Count of successfully processed requests.成功处理的请求数量。
# TYPE vllm:request_success_total counter
vllm:request_success_total{finished_reason="stop",model_name="meta-llama/Llama-3.1-8B-Instruct"} 1.0
vllm:request_success_total{finished_reason="length",model_name="meta-llama/Llama-3.1-8B-Instruct"} 131.0
vllm:request_success_total{finished_reason="abort",model_name="meta-llama/Llama-3.1-8B-Instruct"} 0.0
...
# HELP vllm:time_to_first_token_seconds Histogram of time to first token in seconds. 首个 token 延迟时间的直方图(单位:秒)。
# TYPE vllm:time_to_first_token_seconds histogram
vllm:time_to_first_token_seconds_bucket{le="0.001",model_name="meta-llama/Llama-3.1-8B-Instruct"} 0.0
vllm:time_to_first_token_seconds_bucket{le="0.005",model_name="meta-llama/Llama-3.1-8B-Instruct"} 0.0
vllm:time_to_first_token_seconds_bucket{le="0.01",model_name="meta-llama/Llama-3.1-8B-Instruct"} 0.0
vllm:time_to_first_token_seconds_bucket{le="0.02",model_name="meta-llama/Llama-3.1-8B-Instruct"} 13.0
vllm:time_to_first_token_seconds_bucket{le="0.04",model_name="meta-llama/Llama-3.1-8B-Instruct"} 97.0
vllm:time_to_first_token_seconds_bucket{le="0.06",model_name="meta-llama/Llama-3.1-8B-Instruct"} 123.0
vllm:time_to_first_token_seconds_bucket{le="0.08",model_name="meta-llama/Llama-3.1-8B-Instruct"} 138.0
vllm:time_to_first_token_seconds_bucket{le="0.1",model_name="meta-llama/Llama-3.1-8B-Instruct"} 140.0
vllm:time_to_first_token_seconds_count{model_name="meta-llama/Llama-3.1-8B-Instruct"} 140.0
注意 - 选择直方图桶,以便对广泛的使用场景中的用户最有用,并非一件简单的事情,需要随着时间的推移进行优化。
缓存配置信息
prometheus_client 支持 Info 指标,这些指标等同于一个值永久设为 1 的 Gauge,但通过标签暴露有趣的键值对信息。它用于关于实例的信息,这些信息在启动时不会改变,因此只需要在启动时观察一次,并允许在 Prometheus 中跨实例进行比较。
我们为 vllm:cache_config_info 指标使用了这一概念:
# HELP vllm:cache_config_info LLMEngine CacheConfig 信息
# TYPE vllm:cache_config_info gauge
vllm:cache_config_info{block_size="16",cache_dtype="auto",calculate_kv_scales="False",cpu_offload_gb="0",enable_prefix_caching="False",gpu_memory_utilization="0.9",...} 1.0
然而,prometheus_client从未支持在多进程模式下使用 Info 指标 —— 由于 不明确的原因,我们简单地使用了一个值设为 1 的 Gauge 指标,并将 multiprocess_mode="mostrecent" 作为替代。
LoRA 指标
vllm:lora_requests_info Gauge 指标与此有些相似,不同之处在于其值是当前的墙钟时间,并且每次迭代时更新。
使用的标签名称有:
-
running_lora_adapters: 每个适配器正在运行的请求数,格式为逗号分隔的字符串。 -
waiting_lora_adapters: 类似,但统计等待调度的请求数。 -
max_lora- 静态的“单个批次中最大 LoRA 数量”配置。
将多个适配器的运行/等待计数编码为逗号分隔的字符串似乎不太合理——我们可以使用标签区分每个适配器的计数。这点应该重新审视。
请注意,multiprocess_mode="livemostrecent" 被使用——仅使用当前运行进程中的最新指标。
该功能在 Pull Request #9477 中添加,并且 至少有一个已知用户。如果我们重新审视此设计并废弃旧指标,我们应该通过在 v0 中同时做出更改,并请求该项目迁移到新指标,来减少需要长时间废弃的情况。
前缀缓存指标
在 Issue #10582 中关于添加前缀缓存指标的讨论提出了一些有趣的观点,可能与我们未来的指标方法有关。
每次查询前缀缓存时,我们记录查询的块数和缓存中存在的查询块数(即命中次数)。然而,关注的指标是命中率——即每次查询的命中次数。
对于日志记录,我们预期用户最好通过固定数量的最新查询(目前设置为 1000 次最新查询)来计算命中率。
但对于 Prometheus,我们应当利用其时间序列的特性,允许用户在其选择的时间间隔内计算命中率。例如,计算过去 5 分钟内的命中率的 PromQL 查询:
rate(cache_query_hit[5m]) / rate(cache_query_total[5m])
为此,我们应该在 Prometheus 中将查询和命中记录为计数器,而不是将命中率记录为 gauge。
已弃用的指标
如何弃用
废弃指标不应轻率进行。用户可能没有注意到某个指标已经废弃,当它突然(从他们的角度看)被移除时,即使有等效的指标可用,也会给他们带来不便。
例如,看看如何废弃vllm:avg_prompt_throughput_toks_per_s(并在代码中有注释),然后被移除,之后被用户注意到。
通常:
-
我们应该谨慎废弃指标,尤其是因为很难预测用户的影响。
-
我们应在帮助字符串中包含显著的废弃通知,这些通知会包含在
/metrics输出中。 -
我们应在面向用户的文档和发布说明中列出废弃的指标。
-
我们应考虑通过 CLI 参数将废弃的指标隐藏,给管理员 一个逃生口,在删除之前给他们一些时间。
未实现 - vllm:tokens_total
由 Pull Request #4464 添加,但显然从未实现。这个可以直接移除。
重复 - 队列时间
vllm:time_in_queue_requests 直方图指标由 Pull Request #9659 添加,其计算方式如下:
self.metrics.first_scheduled_time = now
self.metrics.time_in_queue = now - self.metrics.arrival_time
两周后,Pull Request #4464 添加了 vllm:request_queue_time_seconds,我们得到了如下代码:
if seq_group.is_finished():
if (seq_group.metrics.first_scheduled_time is not None and
seq_group.metrics.first_token_time is not None):
time_queue_requests.append(
seq_group.metrics.first_scheduled_time -
seq_group.metrics.arrival_time)
...
if seq_group.metrics.time_in_queue is not None:
time_in_queue_requests.append(
seq_group.metrics.time_in_queue)
这似乎是重复的,应该移除其中一个。后者被 Grafana 仪表板使用,因此我们应当废弃或从 v0 中移除前者。
前缀缓存命中率
如上所述——我们现在暴露的是「查询」和「命中」计数器,而不是「命中率」 gauge。
KV 缓存卸载
在 v0 中,有两个指标与不再相关的「交换」抢占模式有关:
-
vllm:num_requests_swapped -
vllm:cpu_cache_usage_perc
在此模式下,当请求被抢占(例如,为了给 KV 缓存腾出空间以完成其他请求)时,我们将 KV 缓存块交换到 CPU 内存中。这也被称为「KV 缓存卸载」,并通过 --swap-space 和 --preemption-mode 进行配置。
在 v0 中, vLLM 长期支持了 beam 搜索。SequenceGroup 封装了 N 个共享相同提示 kv 块的序列的概念。这使得请求之间可以共享 KV 缓存块,并通过写时复制进行分支。CPU 交换是为这些类似 beam 搜索的情况设计的。
之后,引入了前缀缓存的概念,它允许 KV 缓存块隐式共享。这被证明是比 CPU 交换更好的选择,因为可以按需慢慢逐出块,并且可以重新计算已逐出的提示部分。
在 v1 中,SequenceGroup 被移除,尽管对于「并行采样」(n>1) 需要替代方案。 Beam 搜索已被移出核心 (在 V0 中)。这部分代码很复杂,但对于很少使用的功能来说是多余的。
在 v1 中,由于前缀缓存更好(零开销)并且默认开启,因此预占和重新计算策略应该效果更佳。
未来工作
并行采样
一些 v0 指标仅在「并行采样」上下文中相关。这是指在请求中使用 n 参数来从同一个提示请求多个完成。
作为在 Pull Request #10980 中添加并行采样支持的一部分,我们还应该添加以下指标。
vllm:request_params_n(Histogram)
观察每个已完成请求的 n 参数值。
vllm:request_max_num_generation_tokens(Histogram)
观察每个完成的序列组中所有序列的最大输出长度。在没有并行采样的情况下,它等同于 vllm:request_generation_tokens。
推测解码
一些 v0 指标专门针对“推测解码”。这是指我们使用更快、近似的方法或模型生成候选标记,然后使用更大的模型验证这些标记。
-
vllm:spec_decode_draft_acceptance_rate(Gauge) -
vllm:spec_decode_efficiency(Gauge)
*vllm:spec_decode_num_accepted_tokens_total (Counter)
-
vllm:spec_decode_num_draft_tokens_total(Counter) -
vllm:spec_decode_num_emitted_tokens_total(Counter)
有一个 PR 正在审核中 (Pull Request #12193),将在 v1 中添加「提示查找 (ngram)」推测解码。其他技术也将在后续加入。我们应该在此上下文中重新审视 v0 指标。
注意 - 我们可能需要像处理前缀缓存命中率一样,将接受率公开为单独的已接受和草稿计数器。效率也可能需要类似的处理。
自动扩展和负载均衡
我们的度量标准的一个常见使用案例是支持 vLLM 实例的自动化扩展。
有关 Kubernetes Serving 工作组 的相关讨论,请参见:
这是一个复杂的话题。请参考 Rob 的评论:
我认为这个指标应该专注于尝试估算什么是最大并发,它将导致平均请求长度 > 每秒查询数……因为这实际上是「饱和」服务器的关键。
一个明确的目标是,我们应该公开所需的指标,以检测这个饱和点,管理员可以基于这些指标实现自动伸缩规则。然而,为了做到这一点,我们需要清楚地了解管理员(和自动化监控系统)应该如何判断一个实例接近饱和:
如何确定模型服务器计算的饱和点(即,当请求速率提高时,我们无法获得更多的吞吐量,而是开始产生额外的延迟),从而有效地进行自动伸缩?
指标命名
我们对命名指标的方法可能需要重新审视:
-
在指标名称中使用冒号似乎与「冒号是保留给用户定义的记录规则」相悖。
-
我们的大多数指标遵循以单位结尾的约定,但并非所有指标都这样。
-
我们的某些指标名称以
_total结尾:
如果指标名称以 `_total` 结尾,它将被移除。当暴露计数器的时间序列时,`_total` 后缀将被添加。 这是为了与 OpenMetrics 和 Prometheus 文本格式的兼容性,因为 OpenMetrics 要求 `_total` 后缀。
添加更多指标
添加新指标的想法源源不断:
-
来自其他项目的示例,例如 TGI
-
来自特定用例的提案,如上述的 Kubernetes 自动伸缩主题
-
可能来源于标准化努力的提案,例如 OpenTelemetry 为生成型 AI 制定的语义约定。
我们应该在添加新指标时保持谨慎。虽然添加指标通常比较简单:
-
它们可能很难删除——参见上面的废弃部分。
-
启用时,它们可能会对性能产生显著影响。并且,除非可以默认启用并在生产环境中使用,否则指标通常使用价值有限。
-
它们对项目的开发和维护有影响。每个添加到 v0 的指标都让 v1 的工作变得更加耗时,也许并非所有指标都值得投入持续的维护。
跟踪 - OpenTelemetry
指标提供了系统性能和健康状况随时间的汇总视图,而跟踪则跟踪每个请求在不同服务和组件之间的流动。两者都属于更广泛的「可观察性」范畴。
v0 支持 OpenTelemetry 跟踪:
-
通过 拉取请求 #4687 添加。
-
使用
--oltp-traces-endpoint和--collect-detailed-traces配置。
OpenTelemetry 有一个生成 AI 工作组。
由于指标本身是一个足够大的话题,我们将在 v1 中单独讨论跟踪这一主题。
OpenTelemetry 模型前向与执行时间
在 v0 中,我们有以下两个指标:
-
vllm:model_forward_time_milliseconds(Histogram)——在请求批次中,该请求在模型前向传递中所花费的时间。 -
vllm:model_execute_time_milliseconds(Histogram)——在模型执行函数中花费的时间。包括模型前向、工作线程之间的阻塞/同步、CPU-GPU 同步时间和采样时间。
这些指标仅在启用 OpenTelemetry 跟踪并且使用 --collect-detailed-traces=all/model/worker 时启用。此选项的文档中说明:
收集指定「模块」的详细跟踪。这可能涉及到成本较高和/或阻塞操作,因此可能会对性能产生影响。
这些指标通过 拉取请求 #7089 添加,并在 OpenTelemetry 跟踪中显示为:
-> gen_ai.latency.time_in_scheduler: Double(0.017550230026245117)
-> gen_ai.latency.time_in_model_forward: Double(3.151565277099609)
-> gen_ai.latency.time_in_model_execute: Double(3.6468167304992676)
我们已经有了 inference_time 和 decode_time 指标,所以问题是,是否存在足够常见的用例,能够证明更高分辨率的时间记录值得投入的开销。
由于我们将单独处理 OpenTelemetry 支持的问题,因此这些特定的指标将在那个话题下讨论。