vLLM 性能分析
警告
性能分析仅适用于 vLLM 开发者和维护者,用于了解代码库中不同部分的时间消耗比例。vLLM 终端用户不应启用性能分析,因为它会显著降低推理速度。
使用 PyTorch Profiler 进行分析
我们支持使用 torch.profiler 模块对 vLLM 工作进程进行跟踪。您可以通过设置 VLLM_TORCH_PROFILER_DIR 环境变量来启用跟踪,将其指向您希望保存跟踪文件的目录:VLLM_TORCH_PROFILER_DIR=/mnt/traces/
启动 OpenAI 服务器时也需要设置 VLLM_TORCH_PROFILER_DIR 环境变量。
使用 benchmarks/benchmark_serving.py 时,可以通过传递 --profile 标志来启用分析。
可以使用 https://ui.perfetto.dev/ 查看跟踪文件。
提示
分析时只需发送少量请求,因为跟踪文件可能会变得非常大。此外,无需解压跟踪文件,可以直接查看。
提示
停止分析器时,它会将所有分析跟踪文件刷新到目录中。这需要时间,例如对于 llama 70b 的约 100 个请求数据,在 H100 上大约需要 10 分钟才能刷新完毕。在启动服务器之前,请将环境变量 VLLM_RPC_TIMEOUT 设置为较大的值,例如 30 分钟:
export VLLM_RPC_TIMEOUT=1800000。
示例命令和用法
离线推理
参考 examples/offline_inference/simple_profiling.py 中的示例。
OpenAI 服务器
VLLM_TORCH_PROFILER_DIR=./vllm_profile python -m vllm.entrypoints.openai.api_server --model meta-llama/Meta-Llama-3-70B
benchmark_serving.py:
python benchmarks/benchmark_serving.py --backend vllm --model meta-llama/Meta-Llama-3-70B --dataset-name sharegpt --dataset-path sharegpt.json --profile --num-prompts 2
使用 NVIDIA Nsight Systems 进行分析
Nsight Systems 是一个高级工具,可以暴露更多的分析细节,例如寄存器和共享内存使用情况、注释的代码区域以及低级别的 CUDA API 和事件。
使用您的包管理器安装 nsight-systems。以下是在 Ubuntu 上的示例。
apt update
apt install -y --no-install-recommends gnupg
echo "deb http://developer.download.nvidia.com/devtools/repos/ubuntu$(source /etc/lsb-release; echo "$DISTRIB_RELEASE" | tr -d .)/$(dpkg --print-architecture) /" | tee /etc/apt/sources.list.d/nvidia-devtools.list
apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
apt update
apt install nsight-systems-cli
示例命令和用法
离线推理
对于基本用法,您只需在运行离线推理的任何现有脚本前添加 nsys profile -o report.nsys-rep --trace-fork-before-exec=true --cuda-graph-trace=node。
以下是使用 benchmarks/benchmark_latency.py 脚本的示例:
nsys profile -o report.nsys-rep --trace-fork-before-exec=true --cuda-graph-trace=node python benchmarks/benchmark_latency.py --model meta-llama/Llama-3.1-8B-Instruct --num-iters-warmup 5 --num-iters 1 --batch-size 16 --input-len 512 --output-len 8
OpenAI 服务器
要分析服务器,您需要像离线推理一样在 vllm serve 命令前添加 nsys profile,但必须根据您的基准测试需求指定 --delay XX --duration YY 参数。持续时间用完后,服务器将被终止。
# 服务器
nsys profile -o report.nsys-rep --trace-fork-before-exec=true --cuda-graph-trace=node --delay 30 --duration 60 vllm serve meta-llama/Llama-3.1-8B-Instruct
# 客户端
python benchmarks/benchmark_serving.py --backend vllm --model meta-llama/Llama-3.1-8B-Instruct --num-prompts 1 --dataset-name random --random-input 1024 --random-output 512
实际上,您应将 --duration 参数设置为较大的值。当您希望服务器停止分析时,运行:
nsys sessions list
获取格式为 profile-XXXXX的会话 ID,然后运行:
nsys stop --session=profile-XXXXX
手动终止分析器并生成 nsys-rep 报告。
分析
您可以使用 nsys stats [profile-file]在 CLI 中查看这些分析的摘要,或者通过按照此处的说明在本地安装 Nsight在 GUI 中查看。
CLI 示例:
nsys stats report1.nsys-rep
...
** CUDA GPU Kernel Summary (cuda_gpu_kern_sum):
Time (%) Total Time (ns) Instances Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name
-------- --------------- --------- ----------- ----------- -------- --------- ----------- ----------------------------------------------------------------------------------------------------
46.3 10,327,352,338 17,505 589,965.9 144,383.0 27,040 3,126,460 944,263.8 sm90_xmma_gemm_bf16bf16_bf16f32_f32_tn_n_tilesize128x128x64_warpgroupsize1x1x1_execute_segment_k_of…
14.8 3,305,114,764 5,152 641,520.7 293,408.0 287,296 2,822,716 867,124.9 sm90_xmma_gemm_bf16bf16_bf16f32_f32_tn_n_tilesize256x128x64_warpgroupsize2x1x1_execute_segment_k_of…
12.1 2,692,284,876 14,280 188,535.4 83,904.0 19,328 2,862,237 497,999.9 sm90_xmma_gemm_bf16bf16_bf16f32_f32_tn_n_tilesize64x128x64_warpgroupsize1x1x1_execute_segment_k_off…
9.5 2,116,600,578 33,920 62,399.8 21,504.0 15,326 2,532,285 290,954.1 sm90_xmma_gemm_bf16bf16_bf16f32_f32_tn_n_tilesize64x64x64_warpgroupsize1x1x1_execute_segment_k_off_…
5.0 1,119,749,165 18,912 59,208.4 9,056.0 6,784 2,578,366 271,581.7 void vllm::act_and_mul_kernel<c10::BFloat16, &vllm::silu_kernel<c10::BFloat16>, (bool)1>(T1 *, cons…
4.1 916,662,515 21,312 43,011.6 19,776.0 8,928 2,586,205 199,790.1 void cutlass::device_kernel<flash::enable_sm90_or_later<flash::FlashAttnFwdSm90<flash::CollectiveMa…
2.6 587,283,113 37,824 15,526.7 3,008.0 2,719 2,517,756 139,091.1 std::enable_if<T2>(int)0&&vllm::_typeConvert<T1>::exists, void>::type vllm::fused_add_rms_norm_kern…
1.9 418,362,605 18,912 22,121.5 3,871.0 3,328 2,523,870 175,248.2 void vllm::rotary_embedding_kernel<c10::BFloat16, (bool)1>(const long *, T1 *, T1 *, const T1 *, in…
0.7 167,083,069 18,880 8,849.7 2,240.0 1,471 2,499,996 101,436.1 void vllm::reshape_and_cache_flash_kernel<__nv_bfloat16, __nv_bfloat16, (vllm::Fp8KVCacheDataType)0…
...
GUI 示例:
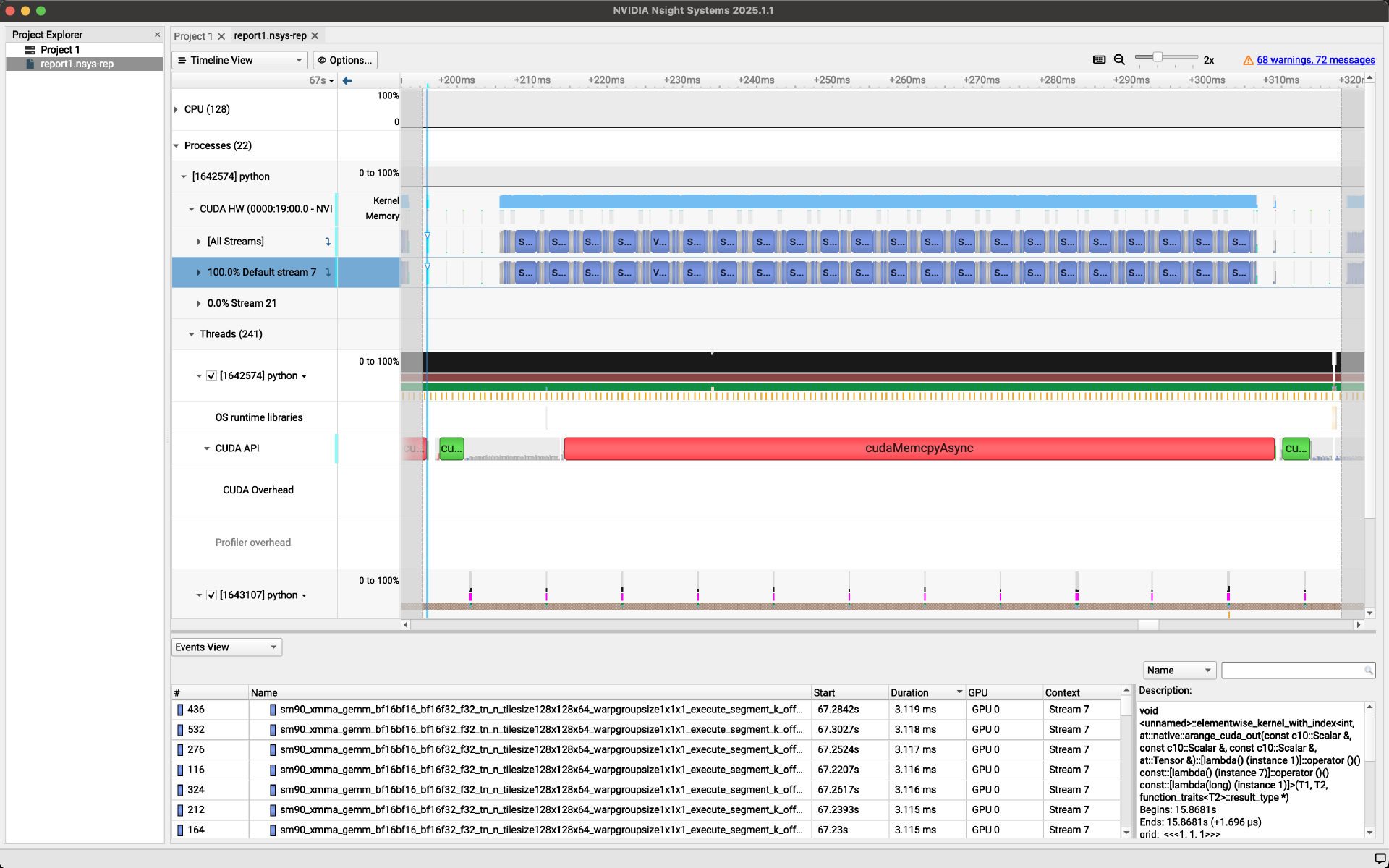
分析 vLLM Python 代码#
Python 标准库包含用于分析 Python 代码性能的 cProfile 模块。vLLM 提供了几个辅助工具,可以轻松地将其应用于 vLLM 的特定代码段。vllm.utils.cprofile 和 vllm.utils.cprofile_context 函数均可用于分析代码性能。
示例用法 - 装饰器
第一个辅助工具是一个 Python 装饰器,可用于分析函数的性能。如果指定了文件名,分析结果将保存到该文件中;如果未指定文件名,分析数据将打印到标准输出。
import vllm.utils
@vllm.utils.cprofile("expensive_function.prof")
def expensive_function():
# some expensive code
pass
示例用法 - 上下文管理器
第二个辅助工具是一个上下文管理器,可用于分析代码块的性能。与装饰器类似,文件名是可选的。
import vllm.utils
def another_function():
# more expensive code
pass
with vllm.utils.cprofile_context("another_function.prof"):
another_function()
分析性能结果
有多种工具可用于分析性能结果,例如 snakeviz。
pip install snakeviz
snakeviz expensive_function.prof